
主讲嘉宾:胡嘉琪
主持人:中关村大数据产业联盟秘书、亚信数据 王维
承办:中关村大数据产业联盟
嘉宾介绍:
胡嘉琪,亚信数据银行解决方案部资深大数据咨询顾问,在大数据应用咨询及数据化运营、数据挖掘领域从业近10年。在金融领域、通信行业主导过众多大数据咨询与数据挖掘项目的成功实施,并具备丰富的大数据行业前沿研究、大数据应用方案咨询经验,近期曾参与贵阳大数据交易所顶层规则设计,以及多家银行/运营商的大数据变革规划咨询,目前主要从事银行业的大数据应用和行业发展动态研究,以及行业解决方案的设计与市场推广。
以下为分享全文:
Hello,大家晚上好!我是亚信银行解决方案部的胡嘉琪,主要负责银行业的大数据应用和行业发展动态研究。首先非常感谢中关村大数据产业联盟与赵秘书长,以及高总为我们提供了这个非常棒的交流互动平台,让彼此的想法与思维能碰撞能出燎亮大数据行业的火花。同时也非常感谢数据资产管理委员会的大力支持。
最近我们银行行业线内部就个人征信领域做了一些探索,今天想借着这个平台,跟大家分享其中的一些思考。征信领域未来将是一片海阔天空,无论数据资产管理、还是各种大数据技术都有大量的应用场景,过中的想象空间非常值得我们去深入研讨。鉴于群里有不少征信领域的专家大咖,因此本次分享的初衷更多是想抛砖引玉,观点如有不当也恳请各位专家指导。
诚如大家所闻所见,个人征信将是一个潜力巨大的市场。目前根据一些券商的估计,如果总体征信行业的评估能够帮助金融系统坏账率降低0.5个点,那按目前中国信贷规模总量计算,就能形成700亿的市场空间,而考虑到中国信贷量的增长速度,这个数字未来将会更加可观。
征信本质上是从人的行为中观察其品格信用的一个过程。也就是我们老祖宗说的”君子之言,信而有征”,好的品格信用是能够被观察到的,而至于要观察什么?经典的信用6C模型告诉我们要看一个人的品德、能力、资本、是否能提供抵押物、还有宏观上的环境与事业的连续性。这些偏重于信贷记录、现金流与财务能力的维度构成了传统征信体系,在过去数据贫乏的时代侧重从金融数据观察信用确实是个无可厚非的好方法,因为其他个人数据基本属于空白。
在中国这种传统的征信体系由于覆盖度低影响到了普惠金融的发展。大量具备潜在良好信用的草根客户无法通过传统征信渠道获取到信贷,因为他们缺乏相应历史信贷记录,无法判断其偿还意愿,且缺乏足够的当前资产作为抵押。对于这些客户,目前相对可行的方法就是引入互联网及运营商、公共事业海量数据开展基于大数据的征信。
俗话说见微知著,人的日常行为同样能反映可能的信用。正如目前业界正在探讨的如使用打车爽约记录、电商退货拒收记录、交易数据、各类社交状态、行为偏好等数据应用于互联网征信的模式,这些相信大家都听闻过。
这里我们主要分享运营商的一个案例,看运营商是如何利用自身数据去做授信应用的。
相比现在如火如荼的互联网征信,实际上运营商尤其是中国移动,是国内比较早开展客户信用体系搭建的。也就是运营商根据对用户的行为、价值、特征进行综合评价,去授予用户一定的信用度,在范围内可透支话费。目的上,客户信用体系是运营商用于中高价值用户维系的重要运营抓手,当然考虑到运营商实际上不低的客户离网率,以及离网率在不同客户群体中的显著差异性分布,信用体系的建立远没有根据客户套餐画几档线这么简单,否则会引致大量的话费拖欠坏账。

从上图可见,运营商具备比较丰富的数据维度,对于信用度评估,运营商一般会考虑几个维度:客户的电信价值、客户流失倾向、客户特征属性、客户本地社交圈、客户风险评估等。
其中电信价值主要考虑用户电信消费水平以及剔除成本后的实际贡献度,贡献度越高的用户能享有更多授信;客户流失倾向通过离网预警模型预测其流失风险,所信用度评估的重要因子;而客户特征属性考察客户人口统计特征,如是否本地常驻居民、在网时长等,其中实践表明,本地常驻居民(非外来务工等)客户的信用水平往往更高;客户交往圈反映了社会人脉关系,相比互联网社交数据,运营商的交往圈数据由于来源于实际通话,其拥有非常重要的参考价值;而客户风险评估主要分析客户历史欠费、停机情况,以及剔除一些渠道养卡等虚假用户,否则一旦向这些用户授信,无异于送羊入虎口了。
基于上述的数据维度,通过模型运算则最终得到了一个用户的话费授信额度。当然模型不是一成不变的,而是需要根据信用体系运营过程中,所收集到的新增实际逾期数据不断优化,定期从新训练模型、开展离线的模型效能比较调优,从而去芜存菁。
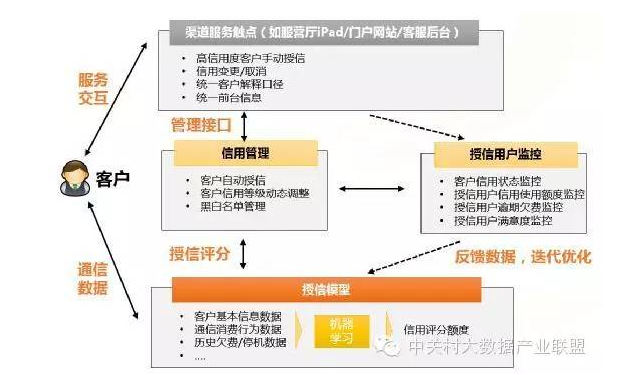
这里有一张图,是运营商整体信用体系的运营示意。一般来说,在运营商信用度模型里面,网龄、是否本地居民、平均停机次数/时长、交往圈数量、月均ARPU等都是比较重要的变量指标。
当然坦率地说,运营商信用评分与实际用户征信还存在较大的区别,在个人征信领域只能做一定的辅助用途。原因在于通信数据仅是个人日常行为的一扇窗口,从中我们只能窥视到用户的通信行为以及一定的人口统计特征。但它连同其它互联网数据以及各类公共事业数据,能逐步还原出人真实的生活状态——比如,一个人是否对朋友言而有信,人脉关系广度,是否按时交纳水电费,从不偷税漏税,平时消费习惯,家庭状态等等。从这些蛛丝马迹,我们可分析用户可能的还款意愿与能力。
然而,现在人的生活状态实际上充满了碎片。很久以前,一个档案就能把我们一生记录下来,而现在我们的每一天都被社交网络、电商、运营商与O2O等瓜分,最终导致了数据割裂。如运营商数据的征信应用,价值应用点主要在通信行为、欠费记录、部分客户信息、上网数据挖掘等,但这些数据可能不足以武断一个人的真实信用状态,而对于大多数其他领域的数据,这个结论也许也是类似的。
从信息论上说,征信就是一个力图降低对一个人信用水平判断不确定性的熵减过程。为了降低不确定性,我们需要引入信息,而每一个信息组合(如运营商数据、电商数据、传统银行信贷数据)的信息量是有限的,因此即使通过最精妙的算法,所降低的不确定性实际存在天花板,最多只能逼近其实际信息量。如把一个用户历史电商交易数据翻个遍,通过各种建模也只能以有50%的置信度,而剩下的风险敞口在缺乏其他数据(如运营商数据、社交数据)下很难化解。
鉴于大数据个人征信还在起步阶段,究竟需要多少类别的有效数据(非低质量数据)综合才能将逾期率控制在合理范围内仍是个待研究的问题。现在非官方的民间征信格局基本上是每一家征信机构坐拥一块数据,如阿里系的交易数据,腾讯的社交数据,并从中开发出相应的征信产品。这里我们会很好奇,假设每一家机构都把自身数据做到了极致,是否都能把风险控制在有效的范围内?至少从阿里出发是认为不太足够的,所以马云才会多次提到数据分享。
举个不太恰当的例子,实际情况有点类似盲人摸象,大家各拥一块数据,纷纷在这块数据的基础上开发信用评估模型,但实际上自己圈定的这块数据的信息量本身,究竟够不够有效评估用户的信用,能真实控制住风险,我想这是整个征信行业需要一起回答的问题。
这里借用一句话,错误的征信比没有征信更加可怕。正如不少P2P声称使用“大数据”手段实施风控,但实际上只是通过自有资金以及“拆东墙补西墙”的资金池把戏去掩盖而已。一旦征信作为服务开放至第三方使用,就如同退潮的沙滩,谁没穿内裤,一目了然。
由于众所周知的原因,我国并未形成良好的个人信用体系,征信业面临的最大困境,在于无数可用。在这个背景下,大家纷纷挖宝互联网数据多少也是一个无奈之举,也是目前能看到的成功概率最高的道路。然而数据却是割据的,每一家征信机构只能在自己院子里耕种,当然我们也非常希望出现八仙过海各显神通的格局,大家均能利用自身的数据禀赋开发出能有效控制风险的征信产品,而这也无疑是中国金融业之福。但倘若大家单靠自身的数据不足以满意地交出征信答卷,而又因为自我保护无法通过数据共享开发更好的征信产品,导致了民营征信行业的踌躇不前,延误了以征信带动中国金融普惠的时机,这是谁都不愿意看到的局面。
中国征信业是一片壮丽巨大的金融蓝海,传统的制度无法扬帆前进,而民营机构带着互联网与创新正开始挑战这片未知海域,而前面等待的也许是一帆风顺,也许是巨浪滔天。如是后者,联合破浪些许是最佳方法。通过流动、共享的数据更好地应对挑战。在流动的数据上,大家比拼的是建模能力与平台能力,以数据普惠推动金融普惠的发展。
今天的分享差不多结束了,期望中国征信业将来能为中国金融多样化提供充足的动力,也希冀流动的数据能进一步为充满想象的征信领域带来真正意义上的大价值,有效推动我国的普惠金融的发展,谢谢大家。
最后尤其要感谢群里的各位征信领域从业专家们,你们的努力,将为中国金融铸造另外一番不同!




