
主持人:谢谢王磊的分享。下一位嘉宾有请Emc的康锦荣先生演讲,他这个标题我是觉得很神秘,横向扩展的数据湖架构,我对大数据技术还是比较外行的,请专家上来给大家讲讲,这个技术用了以后能提升什么。有请!

康锦荣:大家好!我先自我介绍一下,我是来自Emc的技术顾问,我叫康锦荣。

今天给大家介绍的题目看似跟大数据没有关系,但是数据湖的架构就是基于大数据这个概念下提出来的。今天我给大家分享一下,大家都知道我们Emc是专门专注于基础架构的一家厂商,其实最近业界一直有很多的变化,比如IDC提出第三平台的迈进,比如IT的革新,比如一系列的大数据社交网络等等这些概念的提出,我们Emc内部也有一些比较大的变化,一会儿会给大家分享一下。

我们看看这张PPT是现在比较热的一个话题,这个特斯拉公司本身看似像是一家汽车行业的厂商,但是他从根本上颠覆了这个汽车行业,他不单单是从销售角度,从汽车整体的设计理念,包括汽车的维护维修,包括用户对汽车的操作等等,都是基于互联网所定义的。可以看到用户完全可以根据APP去控制自己的汽车,厂商可以根据数据得到这个汽车的运行状态,包括用户在购买的时候也可以在网站上或APP上自己下单,按需采购自己的配置。所以这家公司没有出现的时候,不光是我们用户,包括汽车行业这些其他厂商也是不敢想象的。

现在每个行业都面临着数据架构的转变,我们从数据的角度去探讨这个问题。

Emc技术顾问康锦荣:横向扩展的数据湖架构
比如GE提出了工业2.0的概念,这些企业是比较成功定义了他们自己的架构,他们转型比较成功。举其中一个例子,比如一家保险公司,他们不单单是像咱们说从互联网下单,去采购自己的保险,他们做的别的同行不敢想象的一个动作,他们可以在线理赔自己的保险,极大优化了他们的工作流程。同时他们把这些数据收集过来再循环利用,比如他们可以留住自己的客户,促进自己的商业销售等等。

有些老牌的行业客户没有留住自己的这些客户,在市场上倒下去了,有些大家比较熟悉,今天不是咱们的重点。

一个企业要做大做强,在固定的市场份额下,你不考虑做大,有可能就会缩小,怎么利用好数据,怎么利用好大数据带来的冲击,把它转变为有用的价值,是每个企业都要去深思的问题。
在IDC预测报告里,在未来数据增长量是非常大,将近EB的量级。未来大家可以看一下增长的比例,其中非结构化数据,就是咱们常说的图片、文本或者其他一些格式,我们统称为非结构化数据,它的增长比例非常大。怎么把这些数据利用起来,这些数据如何被利用起来是很关键的问题。

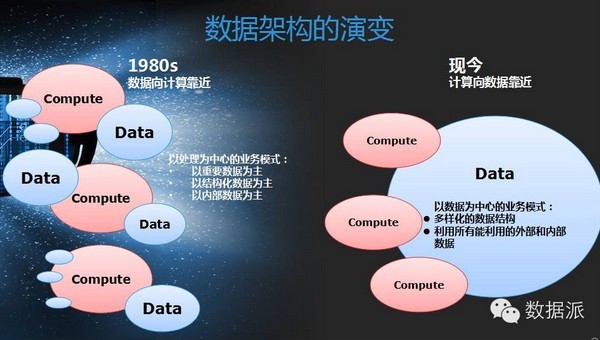
我们再看一下数据架构的演变过程,在80年代一般都是数据向计算靠近的架构,我们每一套业务系统周边围绕自己的主业去获得一些数据,产生一些数据,这些数据多半是一些自己应用内部为主的,往往它的特征,我们归结为一些结构化数据为主。现在可以想象一下,一套大的业务系统,在线的电商,在线的应用举例,比如我这个系统可能有多个入口,除了智能设备,有可能有网站,有B2B的入口。
他们产生不同渠道的数据,怎么把它融会贯通起来,做一些分析,做一些利用。这个大的数据架构就提出来了,看到现在这样一个转变,计算向数据靠齐,各个入口的数据怎么把它融会贯通,在我们大数据的今天,有人就提出了数据湖这个数据架构概念。
大数据这种特点,最近两天各位专家介绍非常详细,有很多三维四维的特性。总结几个点,这些数据没法做到融会贯通,没法统一的存储,存储在一起的时候,这些数据有可能要做很多复杂的数据流动。

这个数据湖概念的提出,我就引用一位数据专家概括的两个数据湖比较简洁的一个特点,他提的特点之一,这个数据湖是用来存储大数据的,首先它是基于一个分布式的文件系统来实现。第二个特点,这些数据湖里的数据要很方便的拿来能做数据分析,同时它要具备一个特点,这些数据不需要签来签去,不需要做复杂的数据流动,这就是数据湖的一个理念。

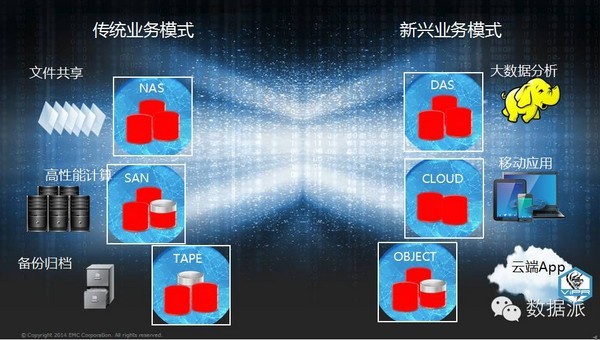
我们看一下今天传统的IT架构,比如我们传统的大的应用系统可能有对外提供的文件共享,同时有可能有主流的高性能计算等等应用,同时有数据库的导出,归档备份,同时提供一些结构化和非结构化数据的数据分析。现在往往都是基于一个一个的数据孤岛来去构建的,这样的话,可能就会带来各种各样的问题。

首先我的数据平台会出现热点,同时我的数据平台可能分布不均,我们需要引用数据湖的架构,把数据纳入到一起,这是我们分布实现的一个理想状态。围绕这个数据湖,我们一定要打造一些企业级的功能。比如最关键的就是我们数据如何达到一个好的保护级别,在这套数据湖里最高可以达到N 4的保护级别。在数据湖架构下可以区分成三种不同的QS的等级,比如最高的类似IO密集型的应用,还有归档性的存储应用,我们可以把它区分出来。
良好的数据管理是很有必要的,这些在数据热点的时候可以放在高一级的存储里,一旦过了在线访问的周期之后,我们可能要转到老数据里,进行数据挖掘。数据安全也是我们比较关注的一个问题,像一些关键的客户他们要给政府做一些数据分析,同时提供一些服务。这些数据不能被更改,这个数据一旦写到存储里,谁都没有办法去更改的。

我介绍了半天,OneFS有几个特点,它是一个横向扩展的一个存储平台,每个节点都有自己的CPU,有内存,也有对外服务的端口,相当于每增加一个控制器,分布式文件系统都有获得容量,这就是横向扩展的一个优势。

我们这回带来一些什么新的东西呢?

首先分布式文件系统最早2000年就有,在今年7月份我们发布了最新的硬件平台和最新的文件系统平台。它的性能已经比2011年我们在公测网站上发布的那个值翻了两倍,同时它提供了更多的访问协议。我下面还会介绍我今天来的时候,我们Emc内部发生了哪些改变。

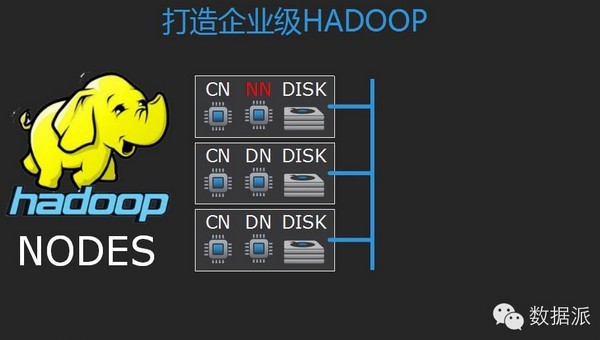
刚才提到数据湖这个架构,数据湖里的数据一定要拿来做分析,现在Hadoop是一个比较好的实现途径。我们具体看一下它的方案实现,首先我们看一下如何来打造一个企业级的Hadoop架构,传统的Hadoop是由传统的X86服务器搭建的,每一台Hadoop节点里,既要承载计算任务,也要承载Hadoop文件系统的数据存储任务。同时大家可以看到我标红的NN那个点,相当于Hadoop服务器,同时有一些隐患存在。

看看我们的设计理念,是把这个计算跟存储分离,这样的话,利用当前高速的计算交换网络,可以达到一些好的效果。大家可以看到首先我们的存储在Hadoop里不需要再复制多份,大家知道Hadoop默认的话,数据在文件系统里要复制三份。这样的话,往往存储利用效率会很低。

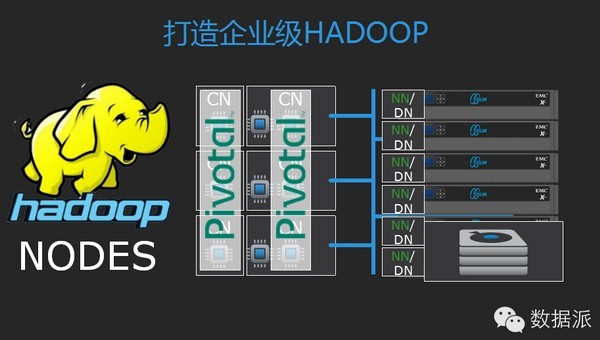
它的存储挪到ONEfs系统里面,ONEfs扮演一个角色,数据不需要再存储多份,只需要用保护机制来做就可以了,从管理上也有很大的好处,可以搭建我们企业级Hadoop架构。
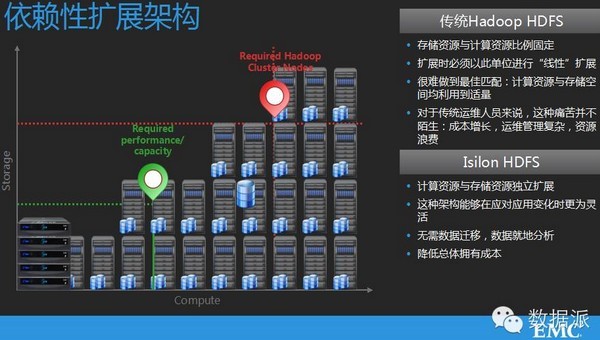
来看一套应用系统在数据湖下面是一个什么样的架构,比如举一个例子,我们应用系统有多个入口,入到里面,我们可以把一些我们的日志,我们的非结构化数据可以放到数据湖里,统一把这些数据做一些数据的挖掘。刚才提到把计算和存储分离的这种Hadoop架构有一些什么样的管理优势呢,对于我们传统的Hadoop,如果计算和存储没有分离的话,可能会有一些问题。
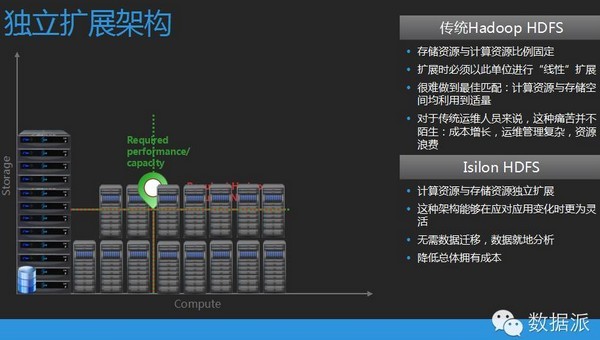
我这个时候有可能我只需要一些性能,但这时候我的存储还空余很多,但是没办法,由于没有分离,我只能同步去扩展,没法达到一个独立扩展的优势。对于这种计算和存储分离的架构,可以看到我们需要计算资源,我们可以选择成本更低的一些刀片用来做计算,需要扩存储扩建,我们单独扩存储节点,这样极大的优化了我们的管理。

除此之外,Hadoop另外一个缺点,它只能基于HDFS来访问,你做一些可视化的图表的查看,你得导出来看。对于这种架构,我们是可以支持一个多协议访问的数据湖,所以数据在里面是互通的。同时这个架构可以支持多个版本的Hadoop,包括开源的还有其他三个商用版的Hadoop提供商。最关键的一点,大家可以看到Hadoop还有一个架构,由VMR提出来的,我们可以把计算完全虚拟化,这也是一个比较大的优点。

我今天数据湖架构的介绍就到这里,谢谢大家!
整理人:付睿
校对人:王斐




