
本讲座选自2015年8月27日在2015中国国际大数据大会主题论坛五──牛津大学NIE金融大数据实验室、数据科学高级研究员、博士王宁所做的题为《大数据和量化金融,从机器交易、高频交易到大数据交易》的演讲。

王宁:很高兴来到这里,我是第二次参加这种会议了。我这次是以第二个身份来的,就是牛津大学NIE金融大数据实验室,代表实验室过来,今天主要分享一下我们实验室做的关于量化金融的思考跟案例。

首先简单介绍一下我们的大数据NIE实验室,是一个全新的实验室,是2013年11月正式成立的,我们实验室的定位是世界主要大学的第一个以金融大数据为研究方向的实验室,我们是交叉学科的实验室,目的是把数据科学运用到金融领域,包括很多学科交叉在一起。因为我们的接口是牛津大学金融数学系,这个系框架上有金融、计算机、统计,我们致力于做一个产学研交流合作的平台。

我们主要研究的方向:包括行非结构化数据。第四就是金融决策,就是我们说的情感分析,怎么用互联网包括社交媒体大数据帮助我们做一些金融决策。最后就是风险控制,也是我们常说的互联网金融怎么样能够把风险控制下来。
我们主要的提出的问题是几个挑战:

金融大数据对行业带来的挑战是什么?
大数据具体在金融领域的主要应用是什么?要真正对行业起到推进作用。
金融更多是关注未来的东西,怎么样能够更好预测未来的东西,降低风险?
最后是决策,怎么设计科学合适的机制,基于大数据机制,最终通过人或者机器进行自动化的决策?
回到我们的主题,金融行业首先核心它是一个决策的机制。一个交易员,自己买股票每天要面对很多决策,是买这个股票还是卖,是买这个基金还是卖这个基金,买是什么时候买,卖是什么时候卖,买还是卖是一个问题,而且这个问题很难找到答案,而且这个问题还是跟时间相关,就是你的时间点要拿捏非常好,如果买得早或卖得早有可能对你金融的盈利模式产生影响。所以最终归根到底不管是交易员的交易还是机器交易,最终金融数学,包括机器交易,核心是一个决策的问题。

一提到决策的问题千百年来有很多决策都是通过人来进行的,这位是诺贝尔经济学奖的得主,他是心理学家拿到经济学奖,他有一个理论就是每个人都有趋利避害的心理,对我有利的东西永远愿意接受,对我有害的东西我永远不太容易接受。这个在学术包括心理学有很多现成的案例,最简单的比方,中国的很多股民都是普通的散户,包括我自己的母亲也是,她买了股票以后股票一跌就不愿意卖了,就放在那里了,股票继续跌,你现在卖了也是在赚钱,你卖得早可能亏得更少,但是她的趋利避害的心理导致她股票一掉就放在那不管了,相反股票一涨她也不愿意卖,觉得会涨更好。所以无论是很资深的交易,还是散户,每个人与生俱来都有趋利避害的心理,他永远希望看到好的事情发生,不好的事情永远不愿意看到。
所以这就导致我们所说的机器交易的发展,因为机器是没有感情的,你跟机器交易,一百块钱和一个亿对机器来说只是一个数字,而且机器不会受情感的影响,也不会受外界环境的影响。所以在西方,特别是华尔街产生一个新的工业就叫机器交易,或者说叫高频交易,这是一个简单的流程。高频交易的历史简单介绍一下,人类第一个股票交易所是在阿姆斯特丹,那时候信息不发达,通过信鸽传递信息,进行套利交易。1983年用了三千万元投资发明了历史上第一个实时的市场数据电脑系统,可以通过这个系统进行金融的计算,所以到今天彭博社在这个领域还是很领先的,在欧美很多的交易员还是非常熟悉彭博社提供的终端。在1996年美国的证监会通过立法允许了这种电子交易,最新的一个数字是美国华尔街时报有一个统计,说现在全世界在西方的金融市场70%的交易都是通过机器进行完成的。
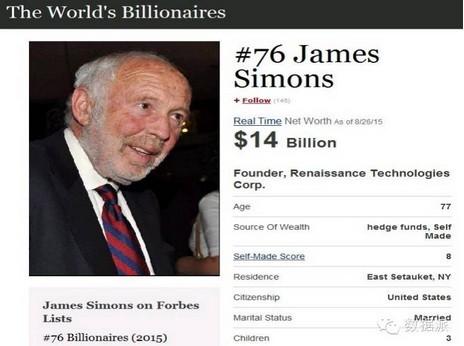
这位是我们的一个前辈,大家知道叫西蒙斯,他建立的一个公司叫文艺复兴,他前身是一个数学家,MIT毕业,然后去美国国防部的机构研究密码,后来跟上司不愉快,就回到美国的大学任数学系主任,做了一段时间觉得没有意思就进入了金融市场,他的公司叫文艺复兴公司。就是全世界做量化投资做得最好的,而且它的平均业绩每年可以达到30%以上的市盈率,它的基金的市盈率是远远超过像巴菲特他们的基金的。他的基金成功的唯一秘诀他是不会跟别人讲的,但是他有一个案例跟大家分享过,他的基金就是通过机器交易,没有任何人的参与,他在华尔街雇了很多高端的理工科毕业生,进行大量计算,通过模型交易,他说人不可信,只有通过机器交易才可以。
这是高频交易的显示度,不到一分钟做了1.8万次交易,频率非常高。高频交易的行业有过一个萎缩的情况,因为高频交易行业进入了一个瓶颈,这个瓶颈就是随着进入这个行业的人越来越多,门槛会提得很高,最后实际很多算法和模型都是基本上公开或者半公开状态,最后拼的是你的硬件和速度,高频交易是和时间赛跑,你的系统的速度怎么样,运算速度怎么样,包括宽带接口速度怎么样可能决定你最后的盈利。最后大家很多公司都是花了很大的钱投资于硬件和网络,实际是以速度的差值赚钱,最终导致很多小的对冲基金进行大量的投资还是竞争不过大基金,最后就倒闭了。所以对冲,整个高频交易行业进入了一个怪圈,有点像当时美国跟俄罗斯的军备竞赛的形式,最后大家花了很多钱投资硬件,通过速度领先于同行业对手,通过速度差值赚钱,所以这个也就是一个高频交易从2013年开始有点慢慢在萎缩的部分的原因。

我们这里讲主要说高频交易现在既然有瓶颈,我们能不能跳出金融的量化的模式,从另外一个角度看,从大数据角度看能不能找到一个新的途径。所以我们就说从高频交易到大数据,大数据现在实际对整个行业,包括金融交易带来一个新的机遇,就是现在我们可以获取的数据远远不是以前的金融的交易,包括买卖的信息。我们可以跳出这个行业,在互联网的社交的领域能够看到有没有其他的可能性。
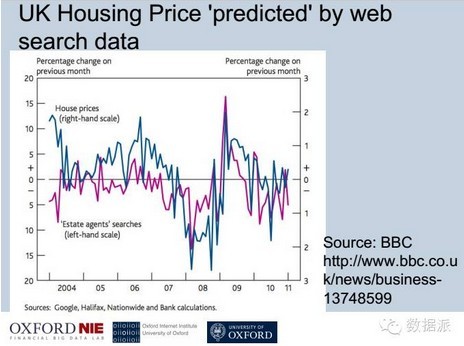
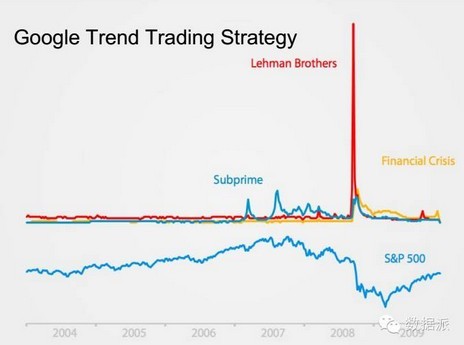
这是一个简单的例子,在一个银行发布的报告,提出在谷歌的搜索引擎里,它可以通过搜索房地产中介关健词流量的变化,可以准确预测英国房价的变化,两者有很高的关联性。基于这个理念也是我的一个朋友,他原来是波士顿大学,现在在英国华威大学,他提出通过谷歌搜索引擎做交易的一个模型,大家可以看到下面是标普500的走势,可以通过不同的关健词,上面是谷歌的关健词的流量变化,可以看到雷曼兄弟关键词大幅变化的时候,标普500有一个下跌的走势,因为当时是雷曼兄弟破产,这样的话就给大家一个很直观的印象,就是有可能搜索量的变化可能会跟股指变化会有很强的相关性。

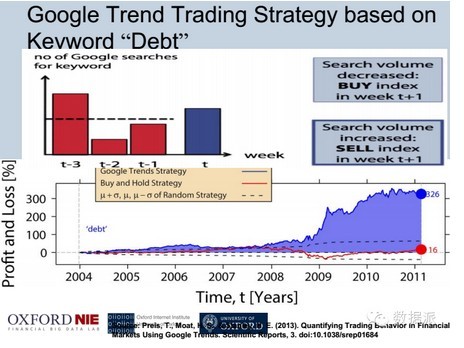
这个就是我的同事托马斯提出的一个模型,通过谷歌的关健词,就是负债务变化,通过谷歌搜索会给你一个流量。这样的话黑线就是美国的道琼斯指数的变化,红色的是负债流量的变化,可以看到红色的流量进行大幅度的增加的时候,实际上随之相应的是道琼斯指数也会产生剧烈的变化。基于这个理论可以提出基于谷歌关键词的模型,这个模型非常简单,就是如果这个关健词在这个星期的流量的变化是降低的时候就可以买股指期货,如果关键词在升高的时候就可以卖股指期货。基于这个模型最后可以分析它总共的市盈率,大家可以看到这个蓝色的都是基于谷歌交易的模型市盈率,从2004年持有到2011年不停地通过每周的交易,最终可以达到300%左右的市盈率。如果是用红色的话,买了之后放在那里只有16%的市盈率,所以说网络上的大数据的模型是远远可以跑赢的。
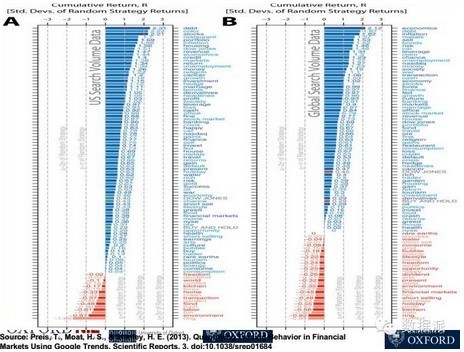
这个交易模型最关键就是你怎么找到所对应的关健词,能够跟相应的金融市场或指数波动有很好的吻合度,所以最后设了几百个关健词,然后跟金融市场的波动和吻合性做了排名,最终发现跟负债相关的关健词跟金融市场吻合度最高,它的市盈率也是最高的。
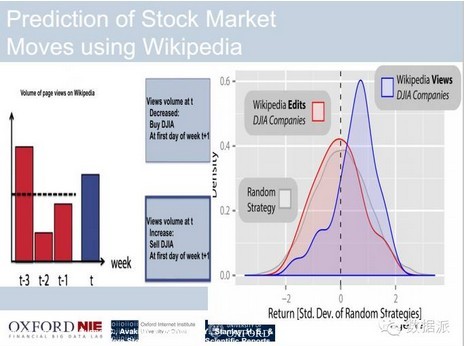
同时我们说如果谷歌搜索引擎可以用来交易的话,那么其他的互联网数据能不能做交易呢?这是用相同的交易模型,只不过用不同的数据,就是维基百科的数据进行交易,大家可以看到蓝色的收益分布是远远高于平均的基础水平的,大概能达到1左右,这样的话就从某种理论上证明虽然它不如谷歌的收益率这么高,但也是正的,所以通过维基百科的数据进行交易也有可能获利。
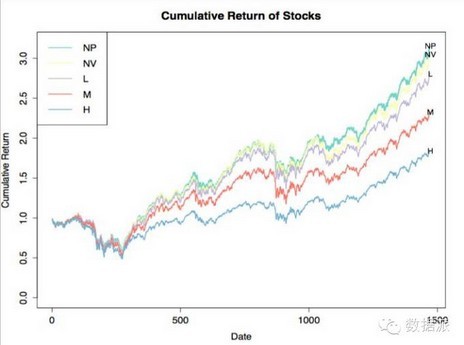
基于以上两个模型,这是我的一个学生,这样的话我们能不能把这个工作做得更细?我们就把维基百科三千个上市公司的所有的浏览量取得以后,从过去的浏览量分析,发现里面很多大的公司尤其在维基百科上浏览量非常大的公司,比如苹果、谷歌这种非常有名的公司,它的市值其实远远被高估了,我们发现三千多个股票里有一些小公司浏览量很低,但它的市值远远被低估了。通过这个模型我们可以把三千个公司划分为五个种类,浏览量高、浏览量适中,还有没有浏览量,还有完全没有网页的,还有浏览量低的。然后设计一个套利模型,就可以卖浏览量高的公司,因为它的市值被高股了,然后买浏览量比较低的公司,按这个模型最终我们的市盈率也可以达到200%左右,这也是一个很好的机会。

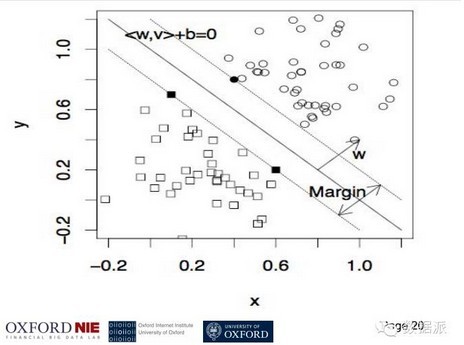
刚才分享了一些怎么用互联网和大数据进行交易,下面就是另外一个主题了。就是在整个大数据领域非常热的,就是怎么把机器学习用到金融里面。这个是一个非常简单的机器学习的模型,我们叫机动向量机,主要做分类的问题,怎么样把圆点跟方框区分开来,它的理论就是距离最大化,找一个数量模型可以让点之间的距离最大化。
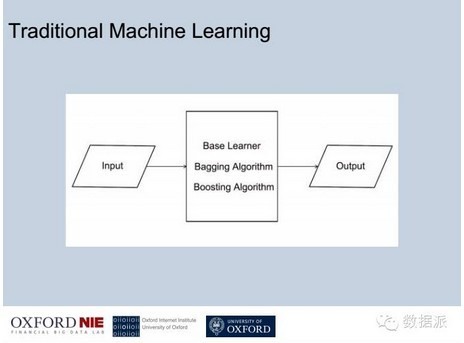
最基础的像SVI模型,拿一个输入,很多的数据训练这个模型,训练到一定程度之后再拿一部分没有被训练的模型去做预测,最终达到输出。
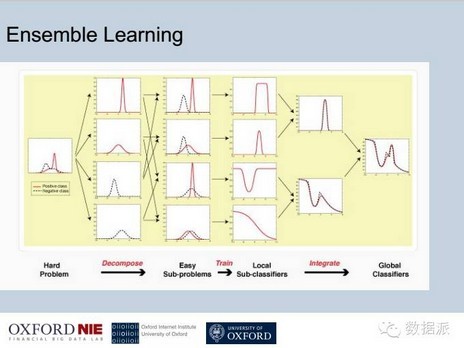
我们所提出的,因为大家知道,单一的模型很简单,对很多非常复杂的金融现象可能不会完全被解释,我们整合很多单一的模型,最后达到整合的机器学习和目的。所以我们把很复杂的问题,比如你要预测明年的金融,可以把它划分成非常小的问题,这些小的问题可能跟他的指数相关,我们可以看他的相对的指数,可以看他的交易额,然后把一个大的问题划分成小的时候,然后把小的问题输入到不同的机器模型做分析,然后做分析之后这个机器模型就会给我们一个分类的问题,最终我们通过最终每个机器模型小的分类整合起来,最终达到全局的分类,这样就是我们所需要的结果。这个模型的好处是不光可以克服单一模型的缺点,可以把很多模型整合在一起,把他们的优势也可以整合在一起。
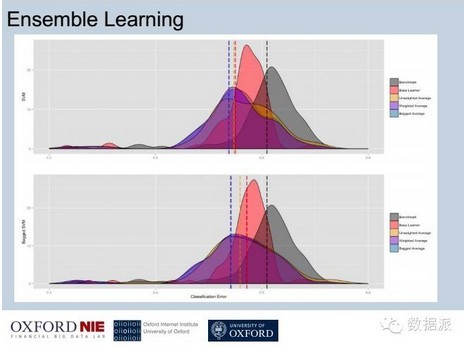
这个是刚才给大家提到的SVI的模型,这个紫色和蓝色的线是我整合的模型的误判率低于单一的模型,模型的平均的误判率是远远低于单一的模型,这样从理论上证明把更多模型整合在一起有这个可能性可以降低误判率,从而提高决策精准度。
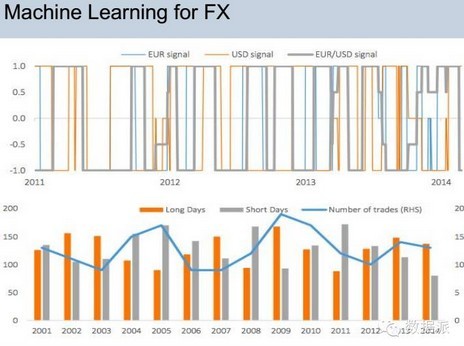
这个是我们用外汇交易的数据,通过互联网的情感分析的数据,通过机械学习可以掌握外汇整编的信号,通过信号输入机器,可以进行买和卖的最终的决策,现在这个模型我们还是在开发之中。
第三个就是想跟大家分享一下我们的案例,就是互联网的一些情感分析,互联网包括社交媒体有大量情感,大家在里面有大量讨论,讨论之后有很多情感引路。比如大家看跌还是看高这个股票,是看高还是看低这个行情?其实有很多情感在里面。另外一个重要因素怎么把情感从现有的互联网分析出来,看它跟金融市场行情的走势联系。

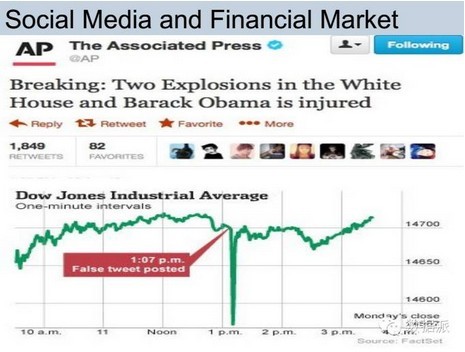
这个是一个例子,现在国内也非常多,很多人通过操纵媒体发布虚假消息,对某支股票进行控制,通过这个渠道进行获利。这是在2013年的时候,在美国的美联社的推特网的帐号被黑客攻击的时候,发布一条消息,白宫有两次爆炸,奥巴马受伤了,发布消息的时间点应声就下落了一百多个点,一个虚假消息导致这么大的波动,这一个消息就导致上百亿就蒸发了,所以媒体对金融市场有非常大的影响。
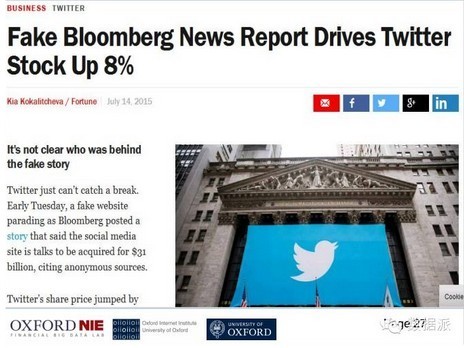
这是彭博社的网站,推特网被攻击之后,黑客做了一个钓鱼网站,就是跟彭博社的网站一模一样,所有的内容都一模一样,只不过里面有一条虚假消息,就是说有一个公司要通过300亿美金收购推特网,结果导致推特网当天就涨了8%,其实这是钓鱼网站,不是蓬勃社的官方网站,但是设置跟蓬勃社一模一样,只是网址有一点差别。这样一个虚假消息很快可以推动金融市场的波动。
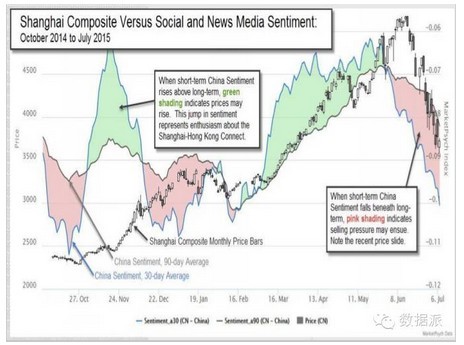
所以我们这么多情感有真有假,怎么把这些情感拿出来机器做分析之后通过它做一些交易,或者是进行一些长期的预判,能够帮助我们决策。这是美国一个基金他们的资料,当时开会他们分享给我的,他们希望通过西方媒体的情感分析,分析全球所有的股市包括金融市场的走势。这是他们对所有的中国的去年10月份到今年6月份网上情感的分析,一个红色的是一个负面的看法,绿色是一个正面的看法,这样大家可以看到基本上整个媒体对股市比较看多的时候其实市场是在往上走的,最有意思是今年6月份的股灾实际上在西方6月初已经在唱空了,通过他们机器模型的分析有很强的做空的信号了,所以6月的股市大跌也是他们理论上通过这个情感可以部分预测出来的。

最后就是我们跟香港的金融数据有限公司合作的一个项目,他们开发了一系列外汇交易,包括股指期货,包括手机软件,通过手机软件产生了大量的交易数据,我们有一个理念,一个好的交易员肯定有一个好的交易习惯,这些交易习惯怎么表示出来?就是通过这些数据都可以反映出来。所以我们帮忙他们怎么通过大量手机平台产生数据,可以找到有潜质的交易员,有的交易员很有潜质自己都不知道。所以也是一个金融的人才的挖掘跟孵化和培养的计划。
整理:顾绍民
校对:祁德力




