10月14日-16日,“ 2015移动开发者大会 · 中国”(Mobile Developer Conference China 2015,简称MDCC 2015)在北京新云南皇冠假日酒店隆重举行。本次大会以“万物互联,移动为先”为主题,邀请国内外业界领袖与技术专家共论移动开发的热点,在实践中剖析技术方案与趋势。

友盟数据平台负责人 吴磊
移动互联网的无处不在催熟了大数据平台,而中国互联网正在面临从IT时代到DT时代的变革,移动互联网与大数据几乎是一种相生相伴的关系。回归到App研发,到后期尤其需要数据与运营。友盟从2010年开始就专注于移动大数据,5年来不仅积累了大量的数据,而且拥有着丰富的技术与经验,那么,友盟大数据平台有着怎样的架构与实践?今天在这里与大家分享一下。
一、架构
架构思想
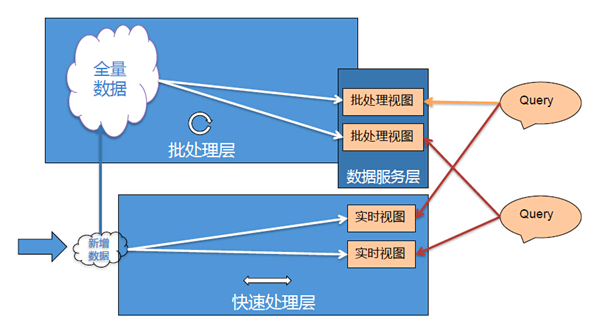
友盟架构主要参考了Twitter提出的Lambda架构思想。如上图所示,最下面是快速处理层,新增数据在快速处理层计算,这部分数据比较小,可以快速完成,生成实时视图。同时,新增数据会并入全量数据集,进行批处理,生成批处理视图。这样,系统同时具有了低延迟实时处理能力,也具有离线大数据处理能力。之后通过数据服务层,把两个视图合并起来,对外提供服务。
数据平台整体架构
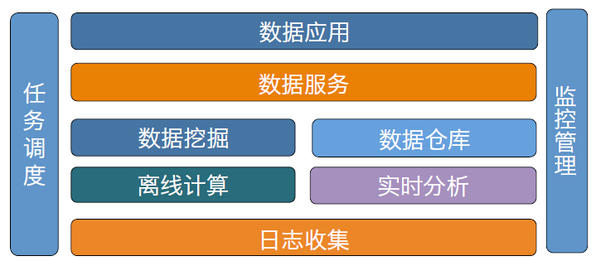
根据友盟的业务特点,数据平台由下向上分成这几个部分:最基础的是日志收集,接下来进入离线计算和实时分析,计算后的结果,会进行数据挖掘,有价值的数据进入数据仓库。接下来会提供一个基于REST Service的数据服务,在此服务之上做各种数据应用,例如:报表、数据分析报告、数据下载等。两边的部分提供辅助的功能,包括任务调度和监控管理。
数据流水线
结合友盟的业务架构和Lambda架构思想,最终的系统如下图所示:最左边是数据采集层,友盟提供手机、平板、盒子的SDK给App集成,App通过SDK发送日志到友盟平台;首先进入到Nginx,负载均衡之后传给基于finagle框架的日志接收器,接着来到数据接入层。
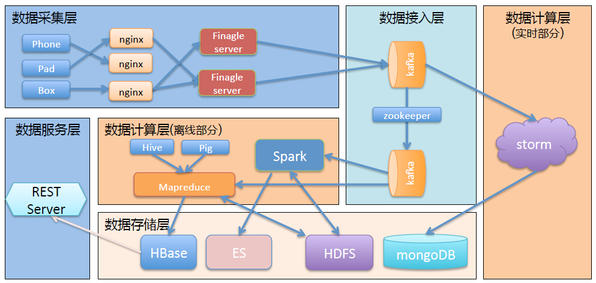
数据接入层让Kalfka集群承担,后面由Storm消费,存储在MongoDB里面,通过Kafka自带的Mirror功能同步,两个Kafka集群,可以分离负载;计算有离线和实时两部分,实时是Storm,离线是Hadoop,数据挖掘用Hive,分析任务,正在从Pig迁移到Spark平台,大量的数据通过计算之后,存储在HFDS上,最后存储在HBase里面,通过ES来提供多级索引,以弥补HBase二级索引的缺失。
二、实践
通过以上的介绍,大家可能对整个大数据平台的结构和概念有了初步的了解。正如Linux之父Linus Torvalds的名言——“Talk is cheap, show me the code!”一样,其实知道是相对容易的,难的是如何去实现。所以接下来,我给大家分享一些友盟在实践中得到的一些经验。
数据采集
首先是从数据采集来说起,数据采集部分面临了很大的挑战,首当其冲便是大流量、高并发和扩展性。友盟的数据平台经历了一个发展的过程。在2010年刚开始的时候,因为快速上线的要求,我们是基于RoR开发的,在后台通过Resque进行一些离线的处理。这个架构,随着互联网的爆发,面临巨大的数据压力,很快就不能适用了。
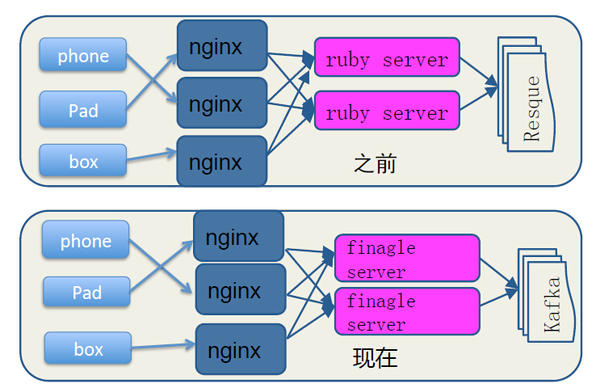
接下来,我们就切换到基于Finagle Server的日志服务器。这个Finagle Server是Twitter开源出来的一个异步服务器框架,很适合移动互联网的访问特点:高并发、小数据量。切换到Finagle Server之后,单台服务器的处理能力得到了极大的提升。同时日志收集服务的无状态特性可以支持横向扩展,所以当面临非常高压力的时候可以简单地通过增加临时服务器来解决。
数据清洗
大数据的特点之一是数据多样化,如果不进行清洗会对后面的计算产生困扰。在数据清洗方面,我们花了很多精力,并踩了很多的坑。
•唯一标识
做数据分析,第一件事情就是要拿到“唯一标识”。Android系统里作为唯一标识的,常用的是IMEI、MAC、Android ID。首先,因为Android碎片化问题,通过API在采集这些数据的时候,常常会有采集不到的情况。
还有其他一些异常的情况,比如有很多山寨机没有合法的IMEI,所以会很多机器共用一个IMEI,导致IMEI重复;有些ROM刷机后会更改MAC地址,导致MAC重复;大部分电视盒子本身就没有IMEI。这种情况下我们单纯用IMEI或者MAC,或者Android ID ,来进行标识的话,就会出现问题。
对此,我们采用的办法是由单独的服务来统一计算。后台会有离线任务来进行计算,发现重复率很高的标识符,加入到黑名单里。在计算的时候,直接跳过黑名单里的标识,换用另一种算法进行计算。
•数据标准化
我们在“数据标准化”方面也遭遇过很多坑,比如:“设备型号”,并不是直接采集model个字段就可以解决的。拿小米3举例,这个手机会有很多版本,不同的批次model字段不一样。对于这种情况,如果不进行统一标准化,算出来的结果肯定有问题。
此外,还会出现多机一型的情况,例如m1,在2011发布的三年后活跃设备数量发生突增。调查发现,原来是其对手厂家在2014年底生产了一款畅销的产品,model字段也叫m1。因此,我们就需要把设备型号,通过专门手段来和产品名称对应上,统一标准化。
在数据标准化过程中,还会遇到“地域识别”的问题。地域识别是用IP地址来识别的。因为中国IP地址管理并不是非常规范,所以经常会出现,上一秒钟大家还在北京,下一秒就到深圳的情况。对于解决这样的问题,我们是选用设备一天中最常出现的IP地址作为当天的地域标识。
还有“时间识别”,也是很大的问题。最开始我们采用的都是客户端时间。但是客户时间有很大的随意性,用户的一个错误设置,就会导致时间不一致;另外一些山寨机会有Bug,机器重启之后,时间直接就变成1970年1月1号了;还有一种可能,产生数据的时候没有网络连接,在重新联网时日志才会汇报到平台,这样的话数据就会产生延迟。
为了解决这些时间不一致的问题,我们统一使用服务器端时间。但是这样又带来了新的问题:统计时间和真实时间的差异,但是这个差异值是从小时间窗口(例如一个小时,或一天)观察出来的,从大的时间窗口来看是正确的。
•数据格式的归一化
友盟SDK经过很多版的进化,上报上来的日志会有多种格式。早期时采用JSON格式,后期则使用Thrift的格式。在数据平台处理的时候,两种格式切换很麻烦,因此在处理之前,我们把它统一成 Protobuf ,来进行后期计算。
数据计算
在数据计算的时候,根据不同业务对于时延的容忍程度的高低,分为实时计算,离线计算和准实时计算。
实时计算,面临的挑战之一是时效性。因为实时计算是对延时非常敏感的,毫秒级的水平。如果说你把不合适的计算,比如一些很耗CPU的计算放进来,会直接导致实时计算的延迟。所以在架构时,需要考量把哪些放到实时部分合适,哪些不适合。另外,实时计算往往会在写数据库时产生IO延迟,需要对实时数据库进行专门优化。对此,我们在实时计算部分选用了MongoDB存储数据,同时不断优化MongoDB的写请求来解决这个问题。
另外一个挑战是突发流量。用户使用App的频率并不均匀,早中晚会有很高的使用率,尤其是晚上10:00-12:00这个时间段会对我们系统带来非常大的压力,得益于之前的架构设计,在达到一定的阈值之后,会触发报警,运维的同学会进行临时扩容来应对这些突发流量。
因为实时计算通常是增量计算,会产生误差积累的问题。Lambda架构决定了实时和离线是两套独立的计算系统,所以必然会出现误差。如果长时间使用实时计算的结果,这个误差会越来越大。现在解决的办法是在实时处理时,不要给太大的时间窗口,比如说最多不要超过一天,超过一天之后,就要开始清理,离线部分的计算每天计算一次,保证在这个时候离线部分的数据计算完成,这样就可以用离线的数据来覆盖实时数据,从而消除这个数据误差。
离线计算,也会面临一些问题。最常遇到的麻烦是数据倾斜问题。数据倾斜这个事情,几乎是天然存在的,比如说一些大App的数据量,和小App的数据量存在着巨大的差距,常常会在离线计算的时候产生长尾现象,并行的MR作业中总是有一两个任务拖后腿,甚至超出单机计算能力。
产生数据倾斜的原因有很多种,针对不同的原因,有不同的解决办法。最常见的原因是因为粒度划分太粗导致的,比如说我们计算的时候,如果以App ID来进行分区,很容易导致数据倾斜。针对这种情况,友盟的解决办法的是进行更细一步的划分,比如通过App ID加设备ID进行分区,然后再将结果聚合起来,这样就可以减少数据倾斜的发生。
第二个问题是数据压缩的问题。离线计算的时候,往往输入输出都会很大,因此我们要注意时时刻刻进行压缩,用消耗CPU时间来换取存储空间的节省。这样做能够节省数据传输中的IO延迟,反而能够降低整个任务的完成时间。
接下来会面临资源调度的困难,因为各种任务优先级是不一样的,比如一些关键的指标,要在特定时间算出来,有些任务则是早几个小时都可以。Hadoop自带的调度器无论是公平调度还是能力调度器都不能实现我们的需求,我们是通过修改Hadoop的度器代码来实现的。
另外还有一类任务对时延比较敏感,但是又不适合放到实时计算中的。这类任务我们称之为准实时任务。例如报表的下载服务,因为是IO密集型任务,放入实时不太合适,但是它又对时间比较敏感,可能用户等三五分钟还是可以接受的,但是等一两个小时就很难接受了。对于这些准实时任务我们之前采用的是通过预留一定资源来运行MR来实现的。现在用Spark Streaming专门来做这些事情。
在进行准实时计算时,里面也有一个资源占用的问题,在预留的过程中,会导致你的资源占用率过低,如何平衡是个问题;第二点很多实时计算的任务,往往也采用了增量计算模式,需要解决增量计算的误差累计问题,我们通过一定时间的全量计算来弥补这个缺陷。
数据存储
数据存储,根据我们之前的计算模式,也分为在线存储和离线存储两部分。在实时部分的计算结果主要存在MongoDB里面,必须对写IO进行优化。离线数据计算结果一般存储在HBase里。但是HBase缺少二级索引。我们引入了Elastic Search,来帮助HBase进行索引相关的工作。
在做数据服务的时候通过数据缓存能够解决数据冷热的问题。友盟数据缓存用的是Redis,同时使用了TwemProxy来作负载均衡。友盟在数据缓存这方面的经验就是需要预加数据,比如:每天凌晨计算完数据之后,在用户真正访问之前,需要把部分计算结果预先加载上去,这样等到用户访问的时候,就已经在内存里了。
数据增值
整个大数据的系统,价值最大的部分,就在于数据增值,友盟目前数据增值主要分两个大的方向。首先是内部数据打通,基于用户事件,结合用户画像、以及和阿里百川合作提供更多的维度信息,来为开发者提供更精准的推送。比如,对一个汽车电商类App,可以圈定一部分有车的用户来推送汽车配件相关信息,然后圈定一部分无车用户来推送售车相关信息。
此外,在数据挖掘方面也做了很多工作。针对现有的设备,进行用户画像相关计算,通过用户画像能够了解用户的属性和兴趣,方便后续的数据横向打通。同时,还针对一些作弊行为设计提供了设备评级产品。
通过数据平台的统计算法和机器学习算法,把现有的所有设备进行评级,哪些是垃圾设备,哪些是真实设备,能够很好的识别出来。这样一来,如果开发者有相关需求,我们可以提供设备评级相关指标,来帮助开发者测评这些推广渠道,到底哪些可信,哪些不可信。




