主讲嘉宾:查礼
主持人:中关村大数据产业联盟副秘书长陈新河
承办:中关村大数据产业联盟
嘉宾介绍:
查礼,2003年博士毕业进入中科院计算所以来一直从事分布式系统的研发工作。作为课题负责人承担过多项国家863重大专项、863国际合作、发改委专项和欧盟第六框架(FP6)国际合作课题。承担863“中国云”一期和二期的大数据计算技术和系统平台研发等课题。曾担任国家863计划“中国国家网格软件研究与开发”课题的技术总负责人,负责CNGrid GOS v3和v4的体系结构和核心实现,领导研发的网格操作系统(GOS)部署在地理分布的12个网格结点上,支持了中国国家网格的建设。CNGrid GOS支持单一系统映像(SSI)和单点登录(SSO)特性,支持分布式计算和存储资源的共享,并为最终用户访问资源提供友好的接口。自2008年开始,领导研究小组与ApacheHadoop 开源社区合作,向ApacheHive开源项目贡献了“行列混合式存储结构”—RCFile技术和实现代码,该技术已被Facebook、阿里巴巴等公司采用。作为“互补式聚簇索引技术”—CCIndex的发明人之一,将该技术应用到淘宝网的“数据魔方”产品中,用以支持实时多维区间查询。作为“Hadoopin China”(现已更名为中国大数据技术大会)大会的发起人和大会主席,该一年一度的会议自2008年举办以来,已成为专注于大数据相关技术方向国内最大的技术大会。本人的研究兴趣包括大规模分布式资源管理,大数据存储和处理关键技术与系统,以及分布式系统性能优化等。相关成果已发表高质量论文数十篇,获得授权专利2项,获得国家科技进步奖2项(2007、2012)。
以下为分享实景全文:
今天想跟各位朋友探讨的题目是“大数据与企业计算”
三个部分内容:
一﹑大数据技术发展趋势;
二﹑开源大数据软件分析;
三﹑企业计算如何利用开源大数据软件
一、大数据技术发展趋势
近年来,越来越多的国内外互联网公司和传统企业都已意识到数据资产化和规模化带来的潜在价值,如何低成本且高效率地存储和处理数百TB乃至 EB 量级的数据成为极大挑战;企业中原本由IT部门主导的自下而上的技术演进变成了由业务和应用主导的自上而下的需求压力,“向数据要价值”使得几乎每个行业都面临着大数据问题。“大数据”引发了新一轮IT工业革命。
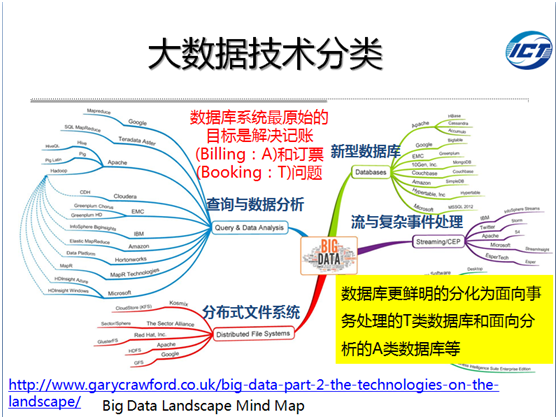
在大数据应用场景中,传统关系型数据库既支持分析又支持事务不再胜任。在关系模型阵营中,以MPP为代表的NewSQL支持SQL并且支持事务,增强了关系模型下的数据处理能力;在非关系模型阵营,以Hadoop为代表的查询与数据分析软件系统则不以支持SQL和事务为目标,以采用大量低成本硬件进行数据处理见长。两者目前有相互借鉴相互融合趋势。此外,数据库开始分化为事务类数据库和分析类数据库。
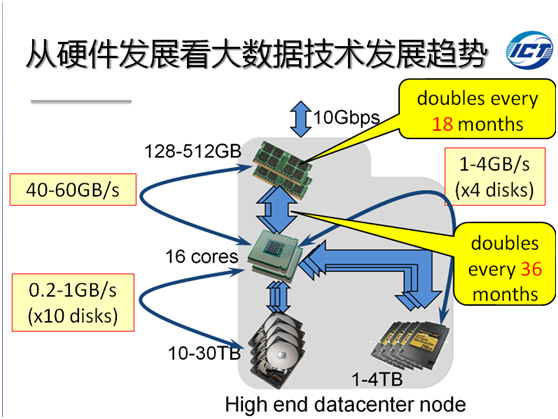
内存与CPU间的带宽是SSD的10倍以上,是机械硬盘的40倍以上,目前物理内存潜力还远没有被挖掘出来。根据摩尔定律,每18个月内存容量将翻一番,每36个月,内存与CPU间的带宽将翻一番。可以想见,对于高并发低延迟的大数据应用来说,未来基于全内存的大数据计算技术是解决该问题的可行方向之一。
查礼: 个人观点,大数据技术和应用的发展趋势可以归纳为以下三点。
1、大数据技术生态环境范围扩大;
2、实时和精准要素更为应用重视;
3、面向系统能效潜力挖掘的差异化技术发展成为重点。
1、大数据技术生态环境范围扩大。克隆了Google的GFS和MapReduce的Apache Hadoop自2008年以来逐渐为互联网企业接纳,并成为大数据处理领域的事实标准。但2013年出现的Spark作为一匹黑马可以说终结了这一神话,大数据技术不再一家独大。由于应用不同导致Hadoop一套软件系统不可能满足所有需求,在全面兼容Hadoop的基础上,Spark通过更多的利用内存处理大幅提高系统性能。此外,Scribe、Flume、Kafka、Storm、Drill、Impala、TEZ/Stinger、Presto、Spark/Shark等的出现并不是取代Hadoop,而是扩大了大数据技术生态环境,促使生态环境向良性和完整发展。今后在非易失存储层次、网络通信层次、易失存储层次和计算框架层次还会出现更多、更好和更专用化的软件系统。
2、实时和精准要素更为应用重视。在全球互联网企业的努力下,Hadoop已经可以处理百PB级的数据,在不考虑时间维度的前提下,价值密度低的数据可以处理了。在解决了传统关系型数据库技术无法处理如此量级的数据之后,业界正在向速度和准确度两个方向要价值。换句话说,如何从大数据中获取更大回报成为业界新的挑战。互联网服务强调用户体验,原本做不到实时的应用在向实时化靠拢,比如前端系统及业务日志从产生到收集入库的延迟从1到2天时间进化到10秒以内。传统企业无法忍受关系数据库动辄几十分钟的查询分析性能,纷纷求助于性价比更好的技术和产品。这些需求使大数据交互式查询分析、流式计算、内存计算成为业界研发和应用的新方向。在实时计算、机器学习和深度学习等技术的支撑下,个性化推荐已经开始从简单的商品推荐走向复杂的内容推荐。根据用户的特性与偏好,推荐内容的特征,以及当时的上下文数据(客户端设备类型、用户所处时空数据等),向特定用户提供个性化的内容推荐服务,内容包括商品(包括电商和零售)、广告、新闻和资讯等。在移动设备和移动互联网飞速发展的时代,个性化推荐将成为用户获取信息最直接的渠道之一。
3、面向系统能效潜力挖掘的差异化技术发展成为重点。今后几年的大数据技术走向将是更高效的系统和更差异化的技术。系统能效将会是业界关注的重点。比如百度云存储万台定制ARM服务器就是典型案例,节电约25%,存储密度提升70%,每瓦特计算能力提升34倍(用GPU取代CPU计算),近10个月以来每GB存储成本降低50%。差异化的技术指的是更加专用的技术,一个系统可能只针对问题的某一个方面,一个问题的解决可能会依赖若干个系统和软件。比如Hadoop将逐渐成为取代磁带库的成熟技术,而直接对接应用的可能会是并行数据库和内存数据库。又如并行数据库更鲜明的分化为面向事务处理的Transaction类数据库和面向分析的Analysis类数据库等。
二、开源大数据软件分析
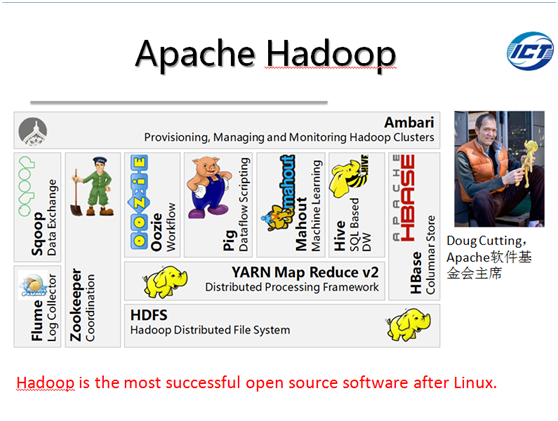
RAID技术通过聚合磁盘I/O使得数据库性能和数据可靠性得以进一步提升。但成本高昂,扩展性差的痼疾使之让位于后起之秀Apache Hadoop这一低成本,扩展性极好的大数据处理工具。2006年诞生的Hadoop可归类为无共享并行数据库系统,同时,Hadoop也引领了数据库从事务(Transaction)与分析(Analysis)型数据库合一到事务与分析型数据库分离的发展趋势。如今,Hadoop已经成为互联网企业进行大数据存储、管理和分析的标准配置。而且,借助开源社区众包的力量,Hadoop已经形成完整而成熟的软件生态环境,其主要组成部分简介如下。
HDFS:以块数据为单位存储并具有副本机制的分布式文件系统
MapReduce:分布式数据处理模式和执行环境
Hive:分布式数据仓库,用于管理HDFS中存储的数据,并提供基于SQL的查询语言(由运行时解释引擎转换为MapReduce作业)用以查询数据
Mahout:其主要目标是构建可扩展的机器学习算法库,目前主要支持三种类型用例,推荐、聚类和分类。
Pig:一种运行在MapReduce和HDFS的集群上的高层(High Level)数据流语言和运行环境,用以检索海量数据集
Oozie:一个对Hadoop上运行作业进行管理的工作流调度器系统。Oozie工作流是放置在DAG(有向无环图 Direct AcyclicGraph)中的一组动作(例如,Hadoop的Map/Reduce作业、Pig作业等),其中指定了动作执行的顺序。使用hPDL(一种XML流程定义语言)来描述DAG
HBase:一个分布式列存储数据库,使用HDFS作为底层存储,同时支持MapReduce的批式计算和点查询(随机读取)
ZooKeeper:一个分布式高可用的协同服务,提供分布式锁相关的基本服务,用于支持分布式应用的构建
Flume:一个高性能的日志收集系统,具有分布式、高可靠、高可用等特点,支持对海量日志采集、聚合和传输。Flume支持在日志系统中定制各类数据发送端,同时,Flume提供对数据的简单处理,并具有分发到各数据接收端的能力
Sqoop:一个可将 Hadoop和关系型数据库中的数据相互迁移的工具。可将关系数据库(例如:MySQL、Oracle、Postgres等)中的数据导入到Hadoop的HDFS中,也可以将HDFS的数据导入到指定的关系数据库中。
Ambari:一个基于Web的Hadoop机群管理和监控工具。Ambari目前已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、HBase、Zookeeper、Sqoop和Hcatalog等
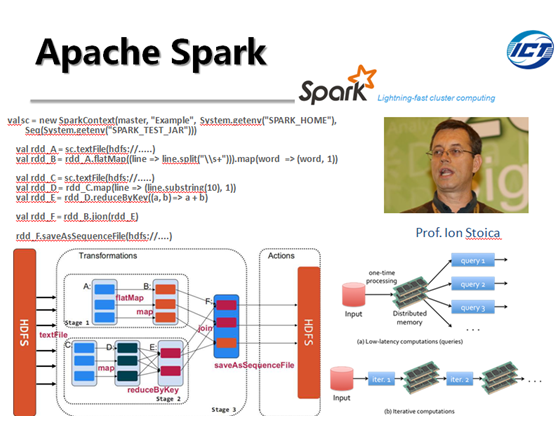
Apache Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms,Machines, and People Lab) 于2011年启动研发的分布式大数据计算软件栈。Spark比Hadoop优越的地方在于可以支持多种类型负载。换句话说,Spark 可以同时支持批式、流式、迭代和实时这四种大数据计算模式。
Spark的核心技术和创新在于引入名为弹性分布式数据集 (ResilientDistributed Dataset,RDD) 的系统抽象。RDD 是分布在一组节点中的只读对象集合。对RDD有两种类型的操作,即转换操作(Transformations)和行动操作(Actions),不像Hadoop只提供了Map和Reduce两种计算方式。转换操作包括map、filter、flatMap、sample,、groupByKey、reduceByKey,、union、join、cogroup、mapValues、sort、partionBy等;行动操作包括count、collect、reduce、lookup、save等。因为RDD是只读的,转换操作会生成一个新的RDD,但并不是立即执行这个计算,只有遇到行动操作的时候才会真正进行计算。这种设计使得Spark可以更加高效的运行。
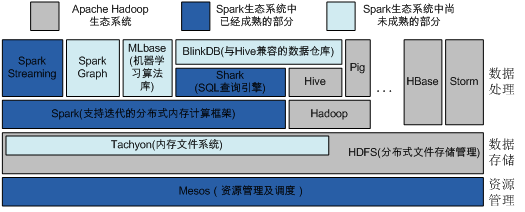
Spark使用Scala开发,默认使用Scala作为编程语言。编写Spark程序比编写Hadoop MapReduce程序要简单的多,写Spark程序的一般步骤就是创建或使用(SparkContext)实例,使用SparkContext创建RDD,然后就是对RDD进行转换操作或行动操作。Spark 中的应用程序称为驱动程序,可以在单节点上或机群上执行。对于机群执行,Spark 依赖于 Mesos 资源管理器。Mesos 为上层应用提供了必要的分布式资源管理与调度功能。
Spark与 Hadoop具有很多相似和相融之处,比如两者均可定位为面向大数据的分布式计算系统,Spark目前还依赖Hadoop中的HDFS作为数据存储等。个人观点,Spark目前还无法脱离Hadoop生态环境单飞,而且应该更专注于自己的强项,即迭代计算和内存优化方面。
这两个已经形成生态系统的开源软件,尤其是Hadoop,目前在互联网、电信运营、网络安全等行业广为应用,已经成为大数据计算工具的代名词。
三企业计算如何利用开源大数据软件

大数据处理虽然源于互联网企业,但是传统企业中保有的结构化数据更多,数据价值密度有可能更大,更容易产生新的应用。面向领域和行业的大数据计算市场方兴未艾!

企业计算领域的大数据技术体系则应遵循“混搭”原则,即源于互联网公司的开源软件产品与企业计算中的成熟关系模型产品按需搭配。除了传统的事务型数据库的应用场景非常明确外,一些新兴的、基于关系模型的分析型数据库的应用场景集中在,存储高度聚合且高价值数据,并面向最终用户的稳定的、可靠性高的企业级数据服务,适用于复杂数据关联加工及分析密集型数据服务;而Hadoop集群的应用场景集中在,不同类型(结构化、半结构化和非结构化)低价值密度数据(原始数据)的可扩展、高可靠、低成本存储,以及它们的流水线式批量化处理,如ETL过程等。
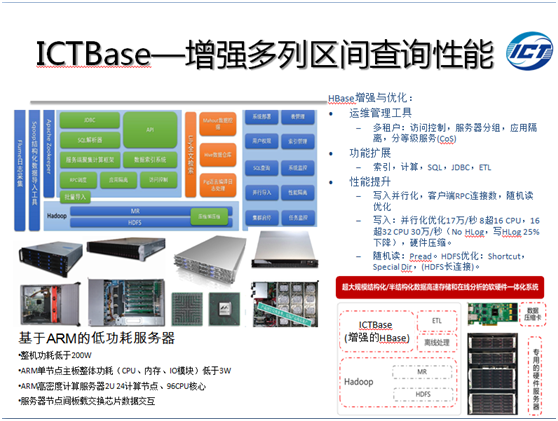
个人观点,面向企业计算,尤其是中国市场,应该采用软硬件一体化的方式,应该能够与基于关系模型的软件无缝对接。在中科院计算所程学旗主任的领导下,我们的团队在开源版本的HBase基础上,集成独有的CCIndex/IRIndex技术、服务端聚集计算技术、SQL解析/执行引擎、硬件加速技术,以及大量的系统优化手段,形成增强了多列区间查询性能的ICTBase软件,并研制了天玑软硬件一体机。
目前ICTBase以及内含关键技术已经有很多非互联网应用案例,用户看中的主要有三点。1、性能好;2、使用门槛低;3、性价比高

个人观点,面向企业计算,尤其是中国市场,应该采用软硬件一体化的方式,应该能够与基于关系模型的软件无缝对接。在中科院计算所程学旗主任的领导下,我们的团队在开源版本的HBase基础上,集成独有的CCIndex/IRIndex技术、服务端聚集计算技术、SQL解析/执行引擎、硬件加速技术,以及大量的系统优化手段,形成增强了多列区间查询性能的ICTBase软件,并研制了天玑软硬件一体机。
目前ICTBase以及内含关键技术已经有很多非互联网应用案例,用户看中的主要有三点。1、性能好;2、使用门槛低;3、性价比高




